

Qu’est-ce qu’un fichier robots.txt ?
Robots.txt est un fichier texte créer par le web master pour expliquer aux robots Web (généralement les robots des moteurs de recherche) comment explorer les pages sur leur site Web.
Le fichier robots.txt fait partie du protocole d’exclusion des robots (REP), un groupe de normes Web qui réglementent la façon dont les robots rampent le web, accèdent et indexent le contenu, et servent ce contenu aux utilisateurs. Le REP comprend également des directives telles que les robots meta, ainsi que des instructions sur la façon dont les moteurs de recherche devraient traiter les liens (tels que « follow » ou « nofollow») des pages internet, sous domaines ou à l’échelle du site en entier.
Dans la pratique, les fichiers robots.txt indiquent si certains user agent (robots d’indexations du Web) peuvent ou ne peuvent pas explorer des parties d’un site Web. Ces instructions d’indexation sont spécifiées par « allow » (Permettre) » ou « disallow » (refuser) le comportement de certains user agent (ou de tous).
Format de base :
User agent : [nom de l’user agent]
Disallow: /[URL à ne pas crawl]
Ensemble, ces deux lignes sont considérées comme un fichier robot.txt complet – bien qu’un fichier robot peut contenir plusieurs lignes d’agents et de directives (c.-à-d., les allow, disallow, crawl-delay, etc.).
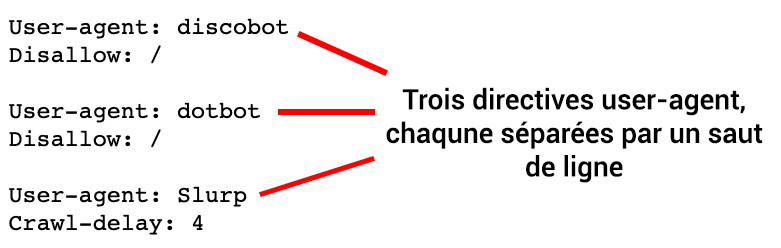
Dans un fichier robots.txt, chaque ensemble de directives est séparé par un saut de ligne :
Format de base :
User agent : [nom de l’user agent]
Disallow: /[URL à ne pas crawl]
Ensemble, ces deux lignes sont considérées comme un fichier robot.txt complet – bien qu’un fichier robot peut contenir plusieurs lignes d’agents et de directives (c.-à-d., les allow, disallow, crawl-delay, etc.).
Dans un fichier robots.txt, chaque ensemble de directives est séparé par un saut de ligne :
Dans un fichier robots.txt avec plusieurs directives d’user-agent, chaque règle d’autorisation ne s’applique qu’à un seul user-agent spécifié dans cet ensemble et séparé d’un saut de ligne. Si le fichier contient une règle qui s’applique à plus d’un user-agent, l’user agent ne fera attention qu’au groupe d’instructions le plus spécifique.
Exemple robots.txt :
Voici quelques exemples de robots.txt en action pour un site www.example.com
Bloquer tous les analyseurs web de tout contenu :
User-agent: *
Disallow: /
L’utilisation de cette syntaxe dans un fichier robots.txt indiquera à tous les crawlers web de ne crawl aucune pages sur www.example.com, y compris la page d’accueil.
Permettre à tous les utilisateurs de web d’accéder à tout le contenu
User-agent: *
Allow: /
L’utilisation de cette syntaxe dans un fichier robots.txt permet aux crawler d’aller sur toutes les pages sur www.example.com, y compris la page d’accueil.
Bloquer un analyseur Web spécifique d’un dossier spécifique
User-agent: Googlebot
Disallow: /exemple-sousdossier/
Cette syntaxe indique au crawler de Google (nom d’user-agent Googlebot) de ne crawl aucune des pages qui contiennent la chaîne d’URL www.example.com/exemple-sousdossier/
Bloquer un user-agent spécifique d’une page Web spécifique :
User-agent: Bingbot
Disallow: /exemple-sousdossier/page-bloquer.html
Cette syntaxe indique au crawler de Bing (Useragent Bingbot) de ne pas crawl la page spécifique : /exemple-sousdossier/page-bloquer.html
Le fonctionnement de robots.txt ?
Les moteurs de recherche ont deux emplois principaux :
- Crawler le web pour découvrir du contenu
- Indexer ce contenu afin qu’il puisse être servi aux personnes qui sont à la recherche d’informations.
Pour explorer les sites, les moteurs de recherche suivent des liens pour passer d’un site à l’autre — pour à la fin, crawler à travers plusieurs milliards de liens et de sites Web.
Ce comportement est parfois connu sous le nom de «spidering».
Après être arrivé sur un site Web, mais avant de l’analysé, le crawler cherchera un fichier robots.txt. S’il en trouve un, il lira ce fichier en premier avant de continuer à parcourir la page. Parce que le fichier robots.txt contient des informations sur la façon dont le moteur de recherche devrait crawler, les informations trouvées lui indiquera d’autres actions de crawl sur ce site particulier. Si le fichier robots.txt ne contient aucune directive qui interdit l’activité d’un user-agent (ou si le site n’a pas de fichier robots.txt), il procédera à l’exploration d’autres informations sur le site.
Autres points du robots.txt à connaître :
- Pour être trouvé, un fichier robots.txt doit être placé à la racine d’un site Web.
- txt est sensible au cas : le fichier doit être nommé « robots.txt » (pas Robots.txt, robots. TXT, ou autrement).
- Certains User-agent (robots) peuvent choisir d’ignorer votre fichier robots.txt. Ceci est particulièrement commun avec des crawler malveillants.
- Le fichier /robots.txt est disponible publiquement : il suffit d’ajouter /robots.txt à la fin de tout domaine pour voir les directives de ce site (si ce site a un fichier robots.txt!). Cela signifie que n’importe qui peut voir quelles pages vous faites ou ne voulez pas être crawler, alors ne les utilisez pas pour cacher les informations d’utilisateur.
- Chaque sous-domaine sur un domaine racine utilise des fichiers robots.txt séparés. Cela signifie que blog.exemple.com et exemple.com devraient avoir leurs propres fichiers robots.txt (à blog.exemple.com/robots.txt et exemple.com/robots.txt).
- C’est généralement une best practice d’indiquer l’emplacement de toutes les fiches sitemaps associées à ce domaine au bas du fichier robots.txt. Voici un exemple :

Syntaxe technique du robots.txt
La syntaxe Robots.txt peut être considérée comme la « langue » des robots.txt. Il y a cinq termes communs que vous êtes probablement amené à rencontrer dans un fichier de robots. Il s’agit notamment de :
– User-agent : le crawler Web spécifique à lequel vous donnez des instructions d’analyse (généralement un moteur de recherche)
– Disallow : La commande utilisée pour dire à un user-agent de ne pas analyser une URL particulière. Une seule ligne « Disallow: » est autorisée pour chaque URL.
– Allow (seulement applicable pour Googlebot): La commande pour dire à Googlebot qu’il peut accéder à une page ou sous-dossier, même si sa page parents ou sous-dossier peut être refusé.
– Crawl-delay: Combien de secondes un crawler devrait attendre avant de charger et d’analyser le contenu de la page. Notez que Googlebot ne reconnaît pas cette commande, mais le délai de crawl peut être défini dans Google Search Console.
– Sitemap : Utilisé pour indiquer l’emplacement de n’importe quelle map de site XML(s) associée à cette URL. Notez que cette commande n’est prise en charge que par Google, Ask, Bing et Yahoo.
Caractères spéciaux :
Quand il s’agit des URL à bloquer ou permettre, les fichiers robots.txt peuvent devenir assez complexe car ils permettent l’utilisation de motifs pour couvrir une gamme d’options URL possibles. Google et Bing honorent deux expressions régulières qui peuvent être utilisées pour identifier les pages ou les sous-dossiers à exclure. Ces deux caractères sont l’astérisque (*) et le signe du dollar ($).
- * est un joker qui représente n’importe quelle séquence de caractères
- $ correspond à la fin de l’URL
Où va le fichier robots.txt sur un site ?
Chaque fois qu’ils viennent à un site, les moteurs de recherche et d’autres robots de web-crawling (comme le crawler de Facebook, Facebot) savent chercher un fichier robots.txt. Mais, ils ne chercheront ce fichier qu’à un endroit précis : A la racine (généralement votre domaine ou votre page d’accueil).
Si un user-agent visite www.exemple.com/robots.txt et ne trouve pas un fichier de robots là-bas, il supposera que le site n’en a pas et va crawler la page (et peut-être même sur l’ensemble du site).
Même si la page robots.txt existait à www.exemple.com/index/robots.txt ou www.exemple.com/accueil/robots.txt, il ne serait pas découvert par les user-agent et donc le site serait traité comme s’il n’avait pas de fichier robots.txt.
Afin de vous assurer que votre fichier robots.txt est trouvé, toujours l’inclure dans votre répertoire principal ou domaine racine.
Pourquoi avez-vous besoin de robots.txt ?
Les fichiers Robots.txt contrôlent l’accès à certains secteurs de votre site. Bien que cela puisse être très dangereux si vous désactivez accidentellement le crawler Googlebot sur l’ensemble de votre site (!!), il y a quelques situations dans lesquelles un fichier robots.txt peut être très pratique.
Voici quelques cas d’usage courant :
- Empêcher le contenu en double d’apparaître dans les SERP
- Garder des sections entières d’un site Web privé
- Empêcher les pages de résultats de recherche interne de se présenter sur un SERP
- Spécifier l’emplacement de sitmap
- Empêcher les moteurs de recherche d’indexer certains fichiers sur votre site Web (images, PDF, etc.)
- Spécifier un délai de crawl afin d’éviter que vos serveurs ne soient surchargés lorsque les crawler chargent plusieurs morceaux de contenu à la fois
Vérifier si vous avez un fichier robots.txt
Vous ne savez pas si vous avez un fichier robots.txt? Il suffit de taper votre nom de domaine, puis ajouter /robots.txt à la fin de l’URL.
Si aucune page .txt n’apparaît, vous n’avez pas actuellement une page robots.txt (live).
Comment créer un fichier robots.txt
Si vous avez trouvé que vous n’aviez pas de fichier robots.txt ou que vous voulez modifier le vôtre, sa création est un processus simple. Cet article de Google vous explique le processus de création de fichiers robots.txt, et cet outil vous permet de tester si votre fichier est configuré correctement.
Best practice SEO
- Assurez-vous que vous ne bloquez aucun contenu ou section de votre site Web que vous voulez crawl.
- Les liens sur les pages bloquées du robots.txt ne seront pas suivis. Cela signifie 1.) À moins qu’ils ne soient également reliés à partir d’autres pages accessibles aux moteurs de recherche (c’est-à-dire les pages non bloquées via robots.txt, meta robots, ou autre), les ressources liées ne seront pas analysées et ne peuvent pas être indexées. 2.) Aucune équité de lien ne peut être passée de la page bloquée à la destination du lien. Si vous avez des pages auxquelles vous souhaitez passer l’équité, utilisez un mécanisme de blocage différent autre que robots.txt.
- N’utilisez pas robots.txt pour empêcher les données sensibles (comme les informations utilisateur privées) d’apparaître dans les résultats SERP. Étant donné que d’autres pages peuvent être reliées directement à la page contenant des informations privées (en contournant ainsi les directives robots.txt sur votre domaine racine ou page d’accueil), il peut encore être indexé.
- Certains moteurs de recherche ont plusieurs user-agent. Par exemple, Google utilise Googlebot pour la recherche organique et Googlebot-Image pour la recherche d’images. La plupart des user-agent du même moteur de recherche suivent les mêmes règles, il n’est donc pas nécessaire de spécifier des directives pour chacun des crawler d’un moteur de recherche, mais avoir la possibilité de le faire ne vous permet d’affiner la façon dont le contenu de votre site est crawler.
Robots.txt vs meta robots vs x-robots
Tant de robots ! Quelle est la différence entre ces trois types de robot? Tout d’abord, robots.txt est un fichier texte, tandis que les meta et les x-robots sont des directives meta. Au-delà de ce qu’ils sont réellement, les trois remplissent tous des fonctions différentes. Robots.txt dicte le comportement de crawl de site ou d’annuaire, tandis que les meta et les x-robots peuvent dicter le comportement d’indexation au niveau de page (ou élément de page) individuel.
Prêt pour passer au display piloté par la donnée ?
Bénéficiez d'un audit display gratuit, et discutons de vos projets
C'est gratuit, et sans engagement
Contactez nousContactez nous